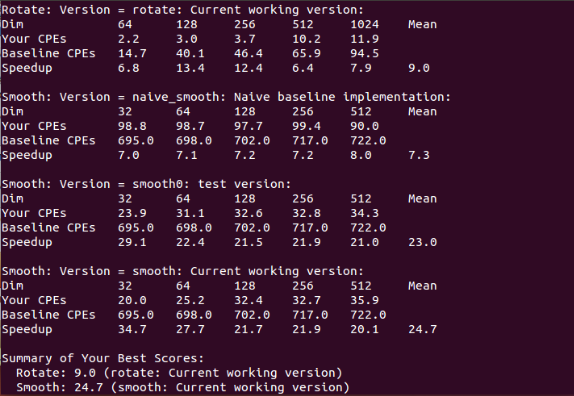
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
|
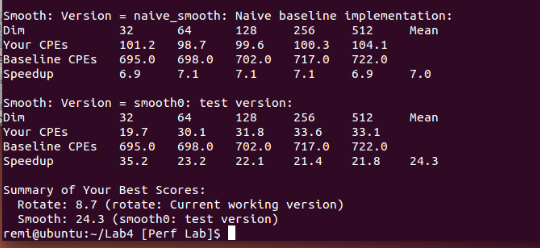
char smooth0_descr[] = "smooth0: test version";
void smooth0(int dim, pixel *src, pixel *dst)
{
int i,j;
//no using avg()
//corners
dst[RIDX(0,0,dim)].red=(src[RIDX(0,0,dim)].red+src[RIDX(1,0,dim)].red+src[RIDX(0,1,dim)].red+src[RIDX(1,1,dim)].red)>>2;
dst[RIDX(0,0,dim)].blue=(src[RIDX(0,0,dim)].blue+src[RIDX(1,0,dim)].blue+src[RIDX(0,1,dim)].blue+src[RIDX(1,1,dim)].blue)>>2;
dst[RIDX(0,0,dim)].green=(src[RIDX(0,0,dim)].green+src[RIDX(1,0,dim)].green+src[RIDX(0,1,dim)].green+src[RIDX(1,1,dim)].green)>>2;
dst[RIDX(0,dim-1,dim)].red=(src[RIDX(0,dim-1,dim)].red+src[RIDX(1,dim-1,dim)].red+src[RIDX(0,dim-2,dim)].red+src[RIDX(1,dim-2,dim)].red)>>2;
dst[RIDX(0,dim-1,dim)].blue=(src[RIDX(0,dim-1,dim)].blue+src[RIDX(1,dim-1,dim)].blue+src[RIDX(0,dim-2,dim)].blue+src[RIDX(1,dim-2,dim)].blue)>>2;
dst[RIDX(0,dim-1,dim)].green=(src[RIDX(0,dim-1,dim)].green+src[RIDX(1,dim-1,dim)].green+src[RIDX(0,dim-2,dim)].green+src[RIDX(1,dim-2,dim)].green)>>2;
dst[RIDX(dim-1,0,dim)].red=(src[RIDX(dim-1,0,dim)].red+src[RIDX(dim-2,0,dim)].red+src[RIDX(dim-1,1,dim)].red+src[RIDX(dim-2,1,dim)].red)>>2;
dst[RIDX(dim-1,0,dim)].blue=(src[RIDX(dim-1,0,dim)].blue+src[RIDX(dim-2,0,dim)].blue+src[RIDX(dim-1,1,dim)].blue+src[RIDX(dim-2,1,dim)].blue)>>2;
dst[RIDX(dim-1,0,dim)].green=(src[RIDX(dim-1,0,dim)].green+src[RIDX(dim-2,0,dim)].green+src[RIDX(dim-1,1,dim)].green+src[RIDX(dim-2,1,dim)].green)>>2;
dst[RIDX(dim-1,dim-1,dim)].red=(src[RIDX(dim-1,dim-1,dim)].red+src[RIDX(dim-1,dim-2,dim)].red+src[RIDX(dim-2,dim-1,dim)].red+src[RIDX(dim-2,dim-2,dim)].red)>>2;
dst[RIDX(dim-1,dim-1,dim)].blue=(src[RIDX(dim-1,dim-1,dim)].blue+src[RIDX(dim-1,dim-2,dim)].blue+src[RIDX(dim-2,dim-1,dim)].blue+src[RIDX(dim-2,dim-2,dim)].blue)>>2;
dst[RIDX(dim-1,dim-1,dim)].green=(src[RIDX(dim-1,dim-1,dim)].green+src[RIDX(dim-1,dim-2,dim)].green+src[RIDX(dim-2,dim-1,dim)].green+src[RIDX(dim-2,dim-2,dim)].green)>>2;
//boarder
for(i=1;i<dim-1;i++){
dst[RIDX(i,0,dim)].red=(src[RIDX(i,0,dim)].red+src[RIDX(i-1,0,dim)].red+src[RIDX(i-1,1,dim)].red+src[RIDX(i,1,dim)].red+src[RIDX(i+1,0,dim)].red+src[RIDX(i+1,1,dim)].red)/6;
dst[RIDX(i,0,dim)].blue=(src[RIDX(i,0,dim)].blue+src[RIDX(i-1,0,dim)].blue+src[RIDX(i-1,1,dim)].blue+src[RIDX(i,1,dim)].blue+src[RIDX(i+1,0,dim)].blue+src[RIDX(i+1,1,dim)].blue)/6;
dst[RIDX(i,0,dim)].green=(src[RIDX(i,0,dim)].green+src[RIDX(i-1,0,dim)].green+src[RIDX(i-1,1,dim)].green+src[RIDX(i,1,dim)].green+src[RIDX(i+1,0,dim)].green+src[RIDX(i+1,1,dim)].green)/6;
}
for(i=1;i<dim-1;i++){
dst[RIDX(i,dim-1,dim)].red=(src[RIDX(i,dim-1,dim)].red+src[RIDX(i-1,dim-1,dim)].red+src[RIDX(i-1,dim-2,dim)].red+src[RIDX(i,dim-2,dim)].red+src[RIDX(i+1,dim-1,dim)].red+src[RIDX(i+1,dim-2,dim)].red)/6;
dst[RIDX(i,dim-1,dim)].blue=(src[RIDX(i,dim-1,dim)].blue+src[RIDX(i-1,dim-1,dim)].blue+src[RIDX(i-1,dim-2,dim)].blue+src[RIDX(i,dim-2,dim)].blue+src[RIDX(i+1,dim-1,dim)].blue+src[RIDX(i+1,dim-2,dim)].blue)/6;
dst[RIDX(i,dim-1,dim)].green=(src[RIDX(i,dim-1,dim)].green+src[RIDX(i-1,dim-1,dim)].green+src[RIDX(i-1,dim-2,dim)].green+src[RIDX(i,dim-2,dim)].green+src[RIDX(i+1,dim-1,dim)].green+src[RIDX(i+1,dim-2,dim)].green)/6;
}
for(j=1;j<dim-1;j++){
dst[RIDX(0,j,dim)].red=(src[RIDX(0,j,dim)].red+src[RIDX(0,j-1,dim)].red+src[RIDX(1,j-1,dim)].red+src[RIDX(1,j,dim)].red+src[RIDX(0,j+1,dim)].red+src[RIDX(1,j+1,dim)].red)/6;
dst[RIDX(0,j,dim)].blue=(src[RIDX(0,j,dim)].blue+src[RIDX(0,j-1,dim)].blue+src[RIDX(1,j-1,dim)].blue+src[RIDX(1,j,dim)].blue+src[RIDX(0,j+1,dim)].blue+src[RIDX(1,j+1,dim)].blue)/6;
dst[RIDX(0,j,dim)].green=(src[RIDX(0,j,dim)].green+src[RIDX(0,j-1,dim)].green+src[RIDX(1,j-1,dim)].green+src[RIDX(1,j,dim)].green+src[RIDX(0,j+1,dim)].green+src[RIDX(1,j+1,dim)].green)/6;
}
for(j=1;j<dim-1;j++){
dst[RIDX(dim-1,j,dim)].red=(src[RIDX(dim-1,j,dim)].red+src[RIDX(dim-1,j+1,dim)].red+src[RIDX(dim-1,j-1,dim)].red+src[RIDX(dim-2,j,dim)].red+src[RIDX(dim-2,j+1,dim)].red+src[RIDX(dim-2,j-1,dim)].red)/6;
dst[RIDX(dim-1,j,dim)].blue=(src[RIDX(dim-1,j,dim)].blue+src[RIDX(dim-1,j+1,dim)].blue+src[RIDX(dim-1,j-1,dim)].blue+src[RIDX(dim-2,j,dim)].blue+src[RIDX(dim-2,j+1,dim)].blue+src[RIDX(dim-2,j-1,dim)].blue)/6;
dst[RIDX(dim-1,j,dim)].green=(src[RIDX(dim-1,j,dim)].green+src[RIDX(dim-1,j+1,dim)].green+src[RIDX(dim-1,j-1,dim)].green+src[RIDX(dim-2,j,dim)].green+src[RIDX(dim-2,j+1,dim)].green+src[RIDX(dim-2,j-1,dim)].green)/6;
}
//common
for(i=1;i<dim-1;i++)
for(j=1;j<dim-1;j++){
dst[RIDX(i,j,dim)].red=(src[RIDX(i,j,dim)].red+src[RIDX(i+1,j,dim)].red+src[RIDX(i-1,j,dim)].red+src[RIDX(i,j-1,dim)].red+src[RIDX(i+1,j-1,dim)].red+src[RIDX(i-1,j-1,dim)].red+src[RIDX(i,j+1,dim)].red+src[RIDX(i+1,j+1,dim)].red+src[RIDX(i-1,j+1,dim)].red)/9;
dst[RIDX(i,j,dim)].blue=(src[RIDX(i,j,dim)].blue+src[RIDX(i+1,j,dim)].blue+src[RIDX(i-1,j,dim)].blue+src[RIDX(i,j-1,dim)].blue+src[RIDX(i+1,j-1,dim)].blue+src[RIDX(i-1,j-1,dim)].blue+src[RIDX(i,j+1,dim)].blue+src[RIDX(i+1,j+1,dim)].blue+src[RIDX(i-1,j+1,dim)].blue)/9;
dst[RIDX(i,j,dim)].green=(src[RIDX(i,j,dim)].green+src[RIDX(i+1,j,dim)].green+src[RIDX(i-1,j,dim)].green+src[RIDX(i,j-1,dim)].green+src[RIDX(i+1,j-1,dim)].green+src[RIDX(i-1,j-1,dim)].green+src[RIDX(i,j+1,dim)].green+src[RIDX(i+1,j+1,dim)].green+src[RIDX(i-1,j+1,dim)].green)/9;
}
}
|