最近在忙着赶紧把去年作死申的国创结题了。。然而我比较宅,都懒得跑出去采集数据集(就是拍照😂)于是想找个爬虫直接把百度图片给扒下来,然而我在网上搜到的代码都比较旧了,不太适用于现在的百度图片(话说最近dl不是很火么按理来说度娘图片的爬虫应该很多啊23333),于是我今早就码了一个简单粗暴的爬虫出来。。。
先看看效果:
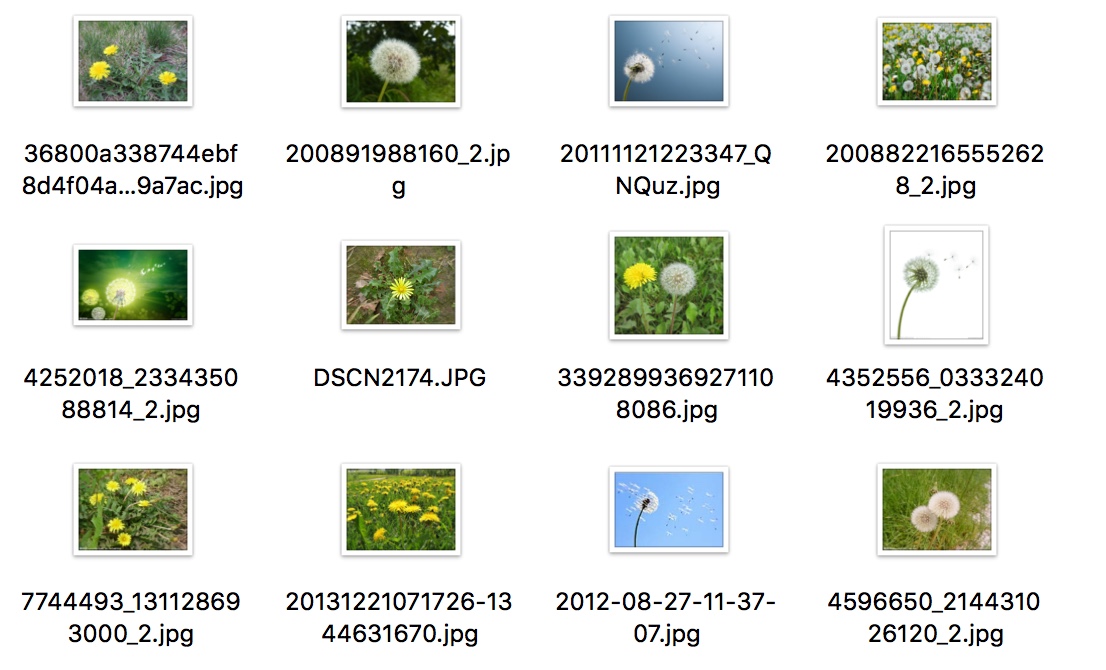
嗯。。我看还阔以
百度图片不太好直接一个正则表达式就完事,可能会抓到大量无关图片,或者是只能抓到预览图。要抓原图还是要分析一下网页代码:
打开开发者工具,随意的搜索一个关键词看看(我搜了一个‘喵’):
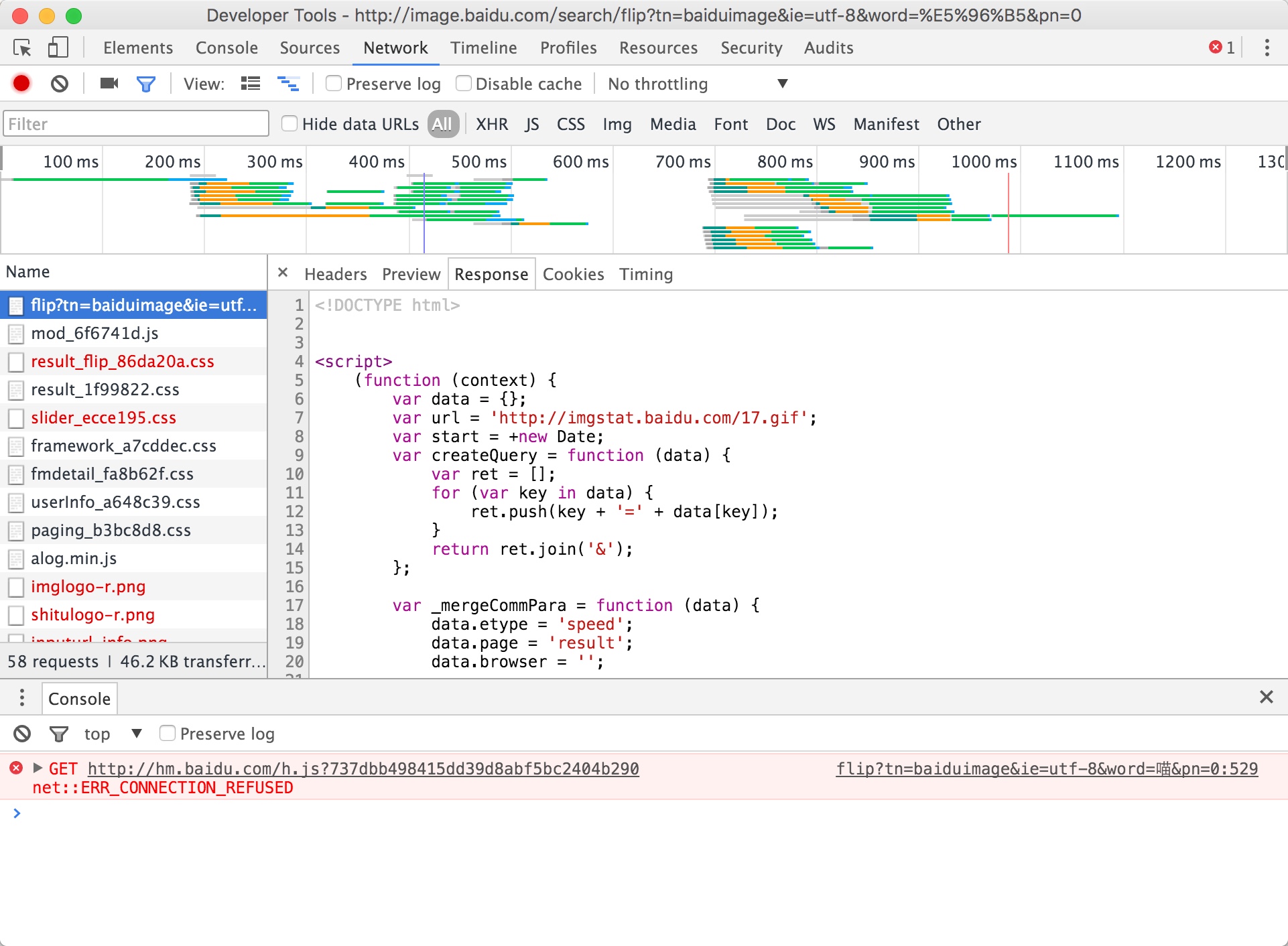
然后看一看就阔以发现这几行应该是搜索返回的一些数据,度娘把数据装在json里面反回了

我要抓的数据是imgData
然后可以看到这里就是原图的地址啦:

再来分析一下url的规律:

直接搜索返回的url很长一段,然而观察一下可以发现有很多不是必须有的
于是可以精简成这样:

嗯,这样规律就很明显了,word里面填关键词,pn从第几个结果开始返回。
分析完之后开始写代码。。说几个关键的点吧。 这两句用来确定url,观察了一下json里面有60个元素,这里dp代表要下载的页数(其实用页书好像不太恰当)。。
| |
然后是
| |
用一个正则表达式把json扒下来存到ipdata中,然后用json.loads(),从字符串中读取json到imgData中。。
之后就是从json里面获取objURL,然后从对应的url中下载图片啦~嗯具体的我不想写了