没错这其实是实验报告。。。不过看起来确实比较像blog文章。。
1. 总体过程
文法分析用Flex:将数据分隔成一个个的标记token (标示符identifiers,关键字keywords,数字numbers, 中括号brackets, 大括号braces, 等等etc.)
语法分析用Bison: 在分析标记的时候生成抽象语法树. Bison 将会做掉几乎所有的这些工作, 只用定义好抽象语法树。
组装用LLVM: 遍历抽象语法树,并为每一个节点生成字节/机器码。
构造一个编译器大概是如下的流程:

2. flex
Flex文件由三个部分组成。或者说三个段。三个段之间用两个%%分隔。 结构如下:
定义段(definitions)
%%
规则段(rules)
%%
用户代码段(user code)
- 定义段: 包含简单名字的定义,可以简化扫描器。
定义方法为:
name definition, 比如digit [0-9] - 规则段: 规则包括模式(正则表达式)和动作(c语言语句),当分析出符合一个模式规则的单词时,执行相应的动作。
- 用户代码段: 所有用户代码都被原样拷贝到文件lex.yy.c中。在这里可以定义一些辅助函数或代码,供扫描器yylex()调用,或者调用扫描器。这一部分是可有可无的。如果没有的话,Flex文件中第二个%%是可以省略的。
3. bison
Bison适合上下文无关文法(Context-free grammar),并采用LALR(1)算法的文法。
当bison读入一个终结符(token),它会将该终结符及其语意值一起压入堆栈。这个堆栈叫做分析器堆栈(parser stack)。把一个token压入堆栈通常叫做移进(shifting)。
bison使用基于类似于BNF的语法,使用定义的好终结符和非终结符来组成我们有效的每一个语句和表达式。每个语法后面都跟有一系列动作,该动作将在这个语法被识别的时候执行。这个过程将会递归地按从叶子符号到根节点符号的次序执行,在这个过程,每一个非终结符最终会被合并为一棵大的语法树。$$符号代表着当前树的根节点。
此外 $1代表了本条规则叶子中的第一个符号。每一条规则中通常赋值一个节点到$$,最后这些规则会合并成一个大的抽象语法树。
4. 使用flex和bison
这里我自定义了一个命令行计算器的文法,BNF如下:
| |
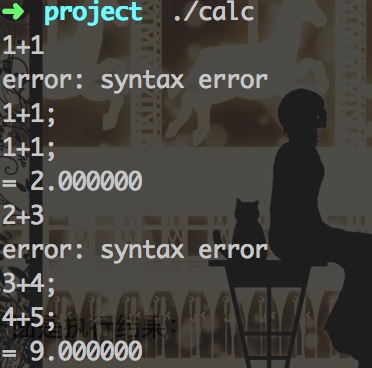
具体代码可见calc.l 和calc.y中,下面是执行结果:
我在此加入了简单的错误处理,当行末尾漏掉分号时,加入错误处理忽略掉这一行,从下一个分号开始重新进行分析,不会直接退出。这在写编译器的时候应该是一个非常有用的功能。
5. llvm
LLVM最初是Low Level Virtual Machine的缩写,定位是一个虚拟机,但是是比较底层的虚拟机。它的出现正是为了解决编译器代码重用的问题,LLVM一上来就站在比较高的角度,制定了LLVM IR这一中间代码表示语言。LLVM IR充分考虑了各种应用场景,例如在IDE中调用LLVM进行实时的代码语法检查,对静态语言、动态语言的编译、优化等。
llvm与传统编译器一样基于三段式架构,结构大概如下图:
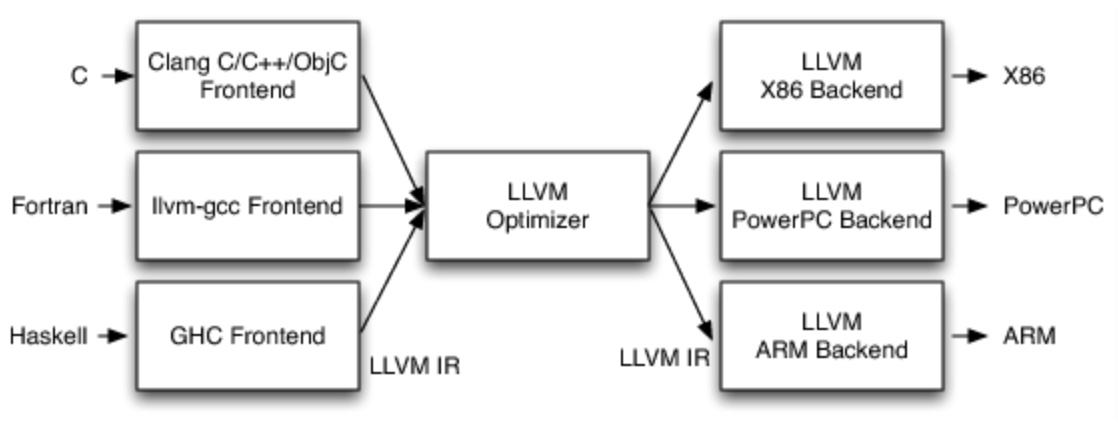
前端负责解析源代码,检查语法错误,并将其翻译为抽象的语法树,优化器对这一中间代码进行优化,试图使代码更高效。后端则负责将优化器优化后的中间代码转换为目标机器的代码,这一过程后端会最大化的利用目标机器的特殊指令,以提高代码的性能。
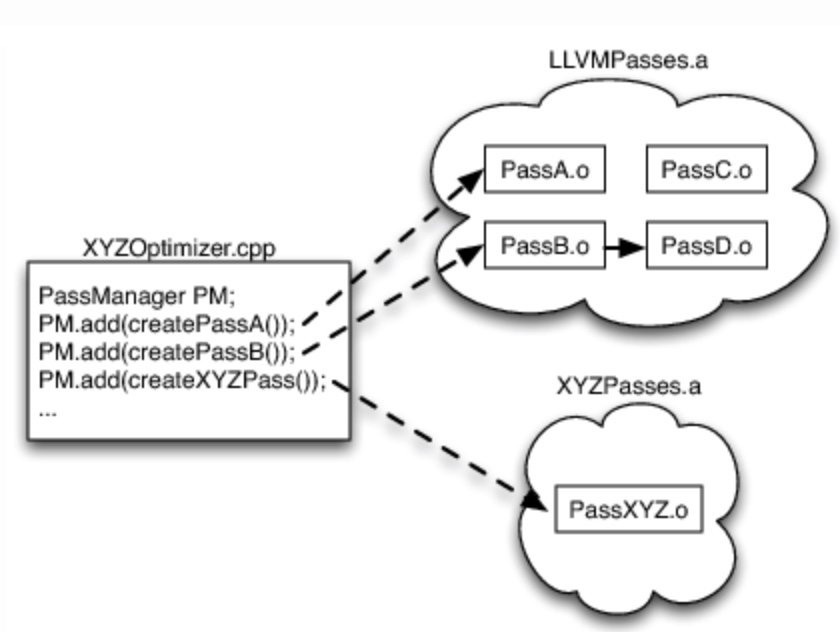
llvm其实从本质上来说它是一个编译器的架构,它实现了一个库,利用这个库可以很容易的实现不同的编译相关的程序。
下面有个比较好的例子可以说明: 假如说我要写一个XYZ语言的优化器,我自己实现了PassXYZ算法,用以处理XYZ语言与其它语言差别最大的地方。而LLVM优化器提供的PassA和PassB算法则提供了XYZ语言与其它语言共性的优化算法。那么我可以选择XYZ优化器在链接的时候把LLVM提供的算法链接进来。
6. llvm IR
可以先自己生成中间代码文件看一看llvm ir:

test.c 代码如下:
| |
可以看到生成的中间代码文件test.ll内容如下:
| |
其中@表示全局变量,%表示局部变量,可以看到llvm中,main函数看做一个全局变量,我定义的变量a、b为局部变量。
alloca表示变量声明,比较类似c语言的malloc。
i32表示该变量占32位。
align表示对齐,这里align 4表示如果数据没有4个字节,它也占用4个字节的空间。
load为装载,store为写入,运算命令有add、sub、mum、div、rems等
ret表示返回。
下面来看一下条件跳转在llvm中怎么翻译:
| |
| |
可以看到icmp指令,用来比较大小,后面跟着条件。
br指令是跳转,可以根据后面布尔表达式的值决定跳转,这里应该是自动把else的情况补全了。
总的来说llvm ir与我们课本接触的汇编语言还是比较类似的,虽然指令集有很多不同,但阅读起来没有太大障碍。
详细的llvm ir可以在llvm的官方文档(http://llvm.org/docs/LangRef.html)中找到。
这个实验主要是去调研现在比较流行、先进的编译技术,现在编译技术基本上很成熟了,想自己定义一种语言也有很多先进、高效的开发工具使用,现代编译技术和课本上的理论知识相差的比较大,之后可以继续阅读相关知识,了解最新进展。