好久没更新…文笔已经退化成小学生水平…
目前打算master毕业后当个远离ml/dl的码农, 毕竟发现自己对数据以及数学并没有那么喜欢, 让我今后日常和数据打交道我觉得我八成会抑郁症, 而且现在和ai相关的工作嘛….emmmmmm, 一言难尽了. 还是写代码能让我开心点…
把之前写的一些东西扔上来存个档, 虽然现在跑路了, 万一哪天又开始搞ml这块了说不定还能看看吧
以下正文
机器人抓取 (robotic grasping) 这个问题牵涉到认知、规划、控制等领域,实现方法也有基于传感、视觉、3D 建模等很多种。传统的基于视觉的机器人抓取系统一般有三个过程:
- 建立图片与现实空间坐标系之间的关系
- 使用计 算机视觉和图像处理的方法对目标进行定位
- 控制机器人对目标进行抓取
和传统的机器视觉问题不同,机器人抓取问题需要通过图片反馈的信息,快速地对机器人作出相应的调整,形成视觉伺服 (servoing) 系统。
1. Cornell - Deep learning for detecting robotic grasps
近年来,由于深度学习方法在计算机视觉领域的巨大成功,Cornell大学提出了一种基于深度学习的机器人抓取系统 paper 。抓取任务可以看作是一种目标检测问题,但不同于一般目标检测的是,这里的目的是找出一个使得抓取目标物体成功率最大的最优抓取 (optimal grasp)。在之前的抓取系统中,对目标定位需要手工设定目标的特征,十分繁琐,鲁棒性也不高。这个系统利用深度学习的方 法自动提取目标的特征,并输出一个抓取矩形 (grasping rectangle) 表示抓取的位置,省去了手工设置特征这一繁琐步骤。
文中的抓取系统如图1所示,该系统从固定在机器人身上的 Kinect 摄像头获取 RGB-D 深度图像信息,并使用一个较小的神经网络搜索出一些可能成功的 抓取矩形。对于每一个候选抓取,从 RGB 图和深度图中提取出原始特征 (raw feature),再将提取出来的特征输入到更大型的神经网络输出每个抓取矩形的得分,最后使用得分最高的抓取矩形作为实际抓取的位置。
 图1 Cornell抓取系统
图1 Cornell抓取系统
文中使用的神经网络模型如图2所示,这两个神经网络使用人工标注的 1000 个抓取数据进行训练,分别用于生成候选抓取矩形和选取最优抓取矩形。
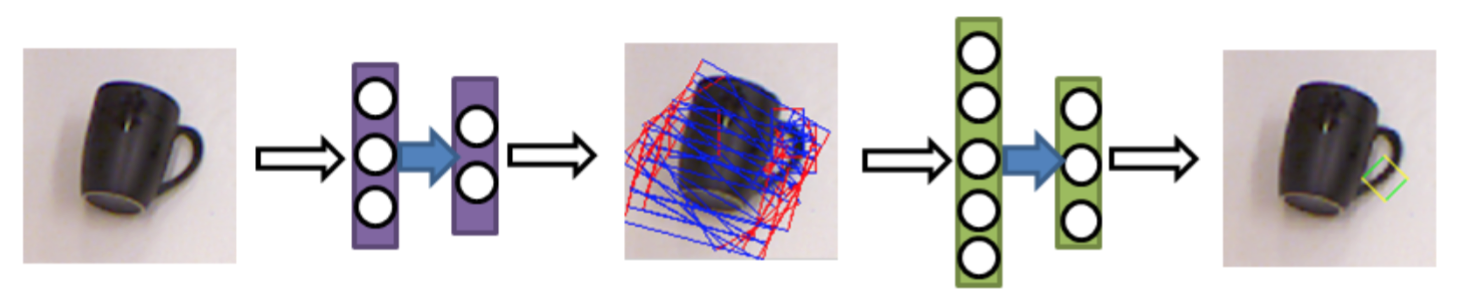 图2 Cornell神经网络模型
图2 Cornell神经网络模型
此文提出的使用深度学习方法得出抓取矩形的机器人抓取系统在当时取得了巨大的成功,使用 PR2 机器人在特定的抓取物品集上达到了 89% 的抓取成功率。
2. CMU - Supersizing self-supervision: Learning to grasp from 50k tries and 700 robot hours
Cornell 的文章中的抓取测试仅在 30 种不同的物体上进行了 100 次抓取实验,虽然达到了 89% 的抓取成功率,但通用性并不强,而且随机性较大。由于 大数据在其他领域的成功,CMU 在 2015 年的工作中 paper 收集了 50,000 个抓取数据,将大数据带入了机器人领域中。
Cornell 文中所使用的数据集是由人工标注的,人工标注有几个缺点:
- 标注耗时长,时间、人工开销大,无法很快地获得大量数据
- 人工标注基于人对图片的语义理解,对于同一个物体可能会有不同的抓取方式
- 人类与机械臂的抓取方式不全相同,所以标注的数据可能存在着与实际比较大的偏差
对于人工标注数据存在的问题,CMU 文中提出了如图3所示的数据收集系统: 输入从摄像头获取的图片,使用 MOG(Mixture of Gaussians) 背景提取算法标定每个物体的大致位置,之后让机器人随机接近一个物体,使用随机的抓取参数进行 抓取,将所有抓取的数据都收集起来,仅标注抓取的成功或失败,利用了700个小时收集到 50,000 个机器人的试错 (trail and error) 数据。
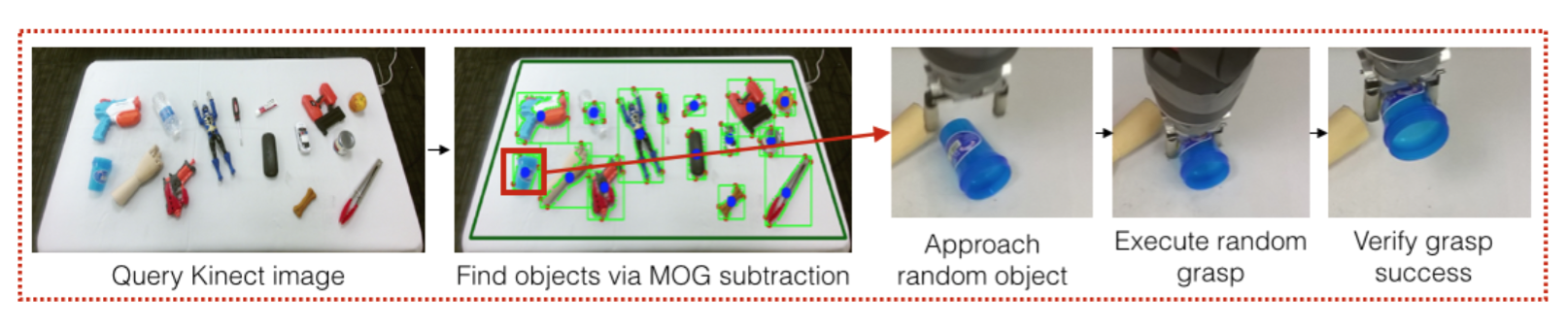 图3 CMU数据收集系统
图3 CMU数据收集系统
 图4 CMU收集的数据集图例
图4 CMU收集的数据集图例
由于神经网络在分类问题上表现的更为出色,CMU 在文中将抓取问题转换为了两阶段的分类问题,首先将机械臂移动到用 MOG 算法定位的物体位置,在 这个位置获取实时图片作为分类器的输入。第一个阶段先训练一个简单的二分类器用于判断该位置是否可以抓取到物体,若判断为能抓取到,进入第二阶段的 分类。第二阶段中使用如图5的 CNN 模型做分类器,前 5 层使用 AlexNet 的结构,并使用在 ImageNet 数据集上预训练好的参数,后两层在收集到的机器人数据集上进行 fine-turning,这里将抓取问题转换成了一个 18 分类问题:将 gripper 旋转的角度 (0◦ − 180◦) 等分为 18 份,将这 18 个旋转角度作为 CNN 分类器的输出。
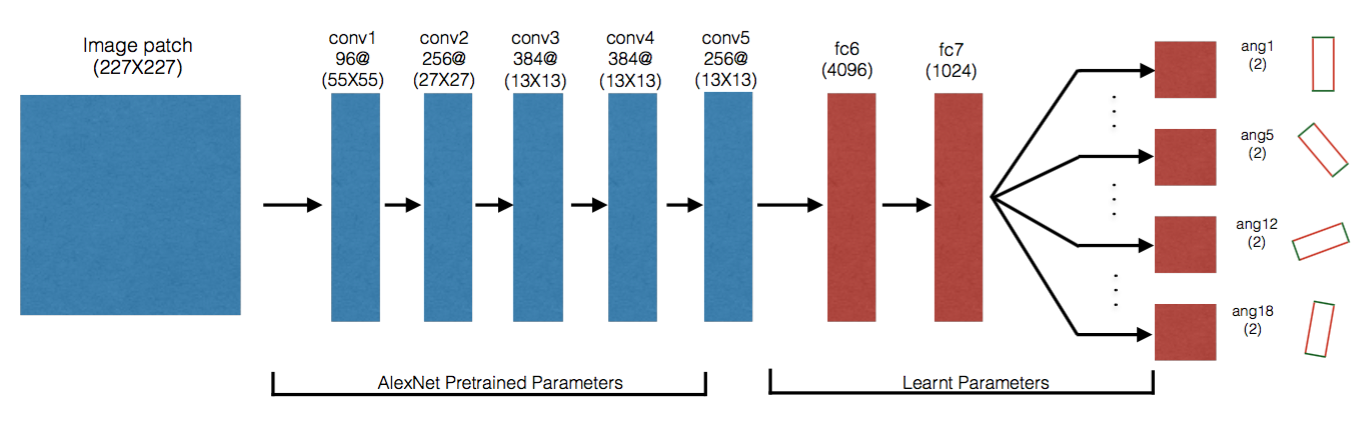 图5 CMU神经网络模型
图5 CMU神经网络模型
CMU 的模型在对 15 件训练数据集未出现的物体进行 3000 次抓取的测试数据集上达到了 79.3% 的预测准确率,高于当时基于学习的抓取方法 (kNN 69.4%, SVM 73.3%)。在 Baxter 机器人的实际抓取测试中,对于 10 种训练集中未出现过的物体的 150 次抓取成功率达到了 66%,证明了该模型有一定的泛化能力,以及将大数据应用于机器人领域的可能性。
3. Google - Learning hand-eye coordination for robotic grasping with deep learning and large-scale data collection
由于看到了数据驱动型的机器人抓取系统的成功,Google 参照 CMU 的做法使用了 14 个机械臂同时进行抓取数据的采集,历时 3 个月采集到了 800,000 个数据paper (图6)。CMU 的工作仅将神经网络使用于抓取系统的抓取动作,仍然使用传统的定位方法接近目标物体,是一个开环 (open-loop) 系统。google 这里实 现了使用深度学习的视觉伺服系统,可以从获取到的视觉信息对机器人进行连续的调整,不需要额外的方法对物体进行定位,是一个闭环 (closed-loop) 系统。
 图6 Google收集的图像数据示例
图6 Google收集的图像数据示例
Google 所使用的神经网络模型如图7所示,将不带 gripper 的图片和实时获取的带 gripper 的图片拼接作为一个输入,将机械臂的控制向量作为另一个输入, 使用神经网络输出此次抓取的成功率。Google 的方法在训练集种未出现的 20 种物体的 120 次抓取测试中的抓取成功率达到了 82.5%。
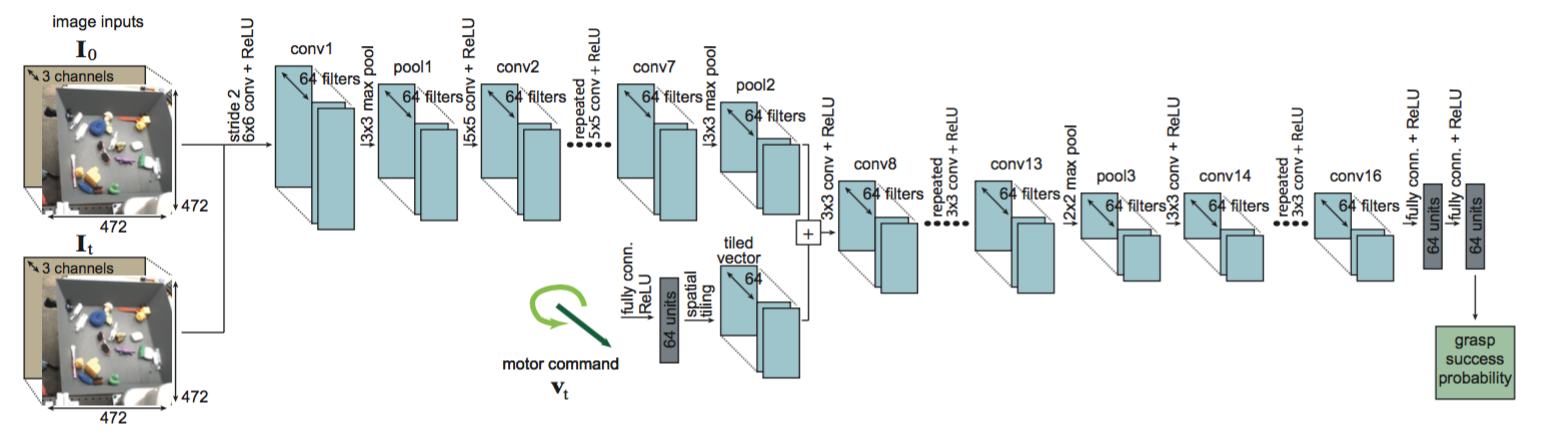 图7 Google的神经网络模型
图7 Google的神经网络模型
基于这样的神经网络模型,文中提出用于伺服系统的算法f(I_t), 伪代码如下: (markdown 渲染latex算法真不咋样…)
| |
Google的神经网络模型输出的结果是由输入的图片与动作向量所推导出的抓取成功概率,输入的图片很好确定,而输入的动作向量较难选取,一个简单的方法是在一定的范围内遍历可能的动作向量,将每个 可能的动作向量输入到神经网络中得到其抓取成功的概率,最后选取出概率最高的动作向量执行。但这种方法的时间、空间开销太大,Google 的论文中提出 了使用 CEM(Cross Entropy Method) 来选取执行的动作向量。
CEM 是一种简单的不基于梯度的优化算法,在每次迭代中对一批 N 个值进行采样,将高斯分布拟合到这些样本中的 M 个最优的上面,然后从该高斯分布 中采样出新的 N 个样本,Google在这里使用 N = 64 和 M = 6,并执行 CEM 的三次迭代以确定最佳的动作向量 v_star, 伪代码如下:
| |
当选出了 v_star 后,就可以按照之前的伺服算法 f(I_t) 来建立伺服系统了.